
Using Tamr’s metadata enrichment, discovery, and standardization to unlock new possibilities in data management

At the genesis of any data-driven initiative or project, we must first find and access the relevant data in our organization to pull together. Better yet if the data we find can be inter-operable or re-usable across both new and old use cases.
But how often is this process easy?
While there is a growing trend of being compliant to FAIR principles in data management, experienced data practitioners know that achieving this state is easier said than done.
However, with the help of Tamr, upgrading data management expectations has become a lot simpler. Tamr’s effectiveness is especially apparent for organizations currently relying on large, de-centralized data management processes; the ability to leverage machine learning for linking data sets across the organization not only make data more accessible, but greatly enables large data transformation initiatives for enterprises that may at first seemed impossible without a complete change over of how the company operates.
In a previous post, I described how Tamr’s agile data mastering capabilities can augment the effectiveness in data searchability and access when using data catalog and management tools. In this post, I’d like to further detail situations where using Tamr on metadata can:
- Enrich metadata for actionable analytics
- Simplify the discovery of new data model schemas, and
- Support the foundation for integrating disparate data sources into standardized data outputs.
Metadata Enrichment
The previous post’s example of applying Tamr on an organization’s metadata is to enrich the metadata of data catalog views with attributes that can increase searchability within a catalog. However, it is important to realize that even outside of the cataloging tool, Tamr’s generated metadata can also be used for identifying other relevant attributes, streamline the identification of disparate attributes, and the support analytics executed on data assets.
Data Relevance – Is one column attribute similar to another?
Even with a large data catalog, it may still not be obvious what data is available for your specific data project without spending a lot of time digging through it. This problem is common among organizations using catalog software; most cataloging tools are made to optimize for data governance rather than access and usability.
To tackle this challenge, Tamr can be used to group together data attribute names across datasets based on various configurations of granularity such that there are multiple ways to find relevant data attributes.
In the below example, it may be difficult to determine at-a-glance whether study_id, geneid, and ensembl_id are related just from the table and column names.
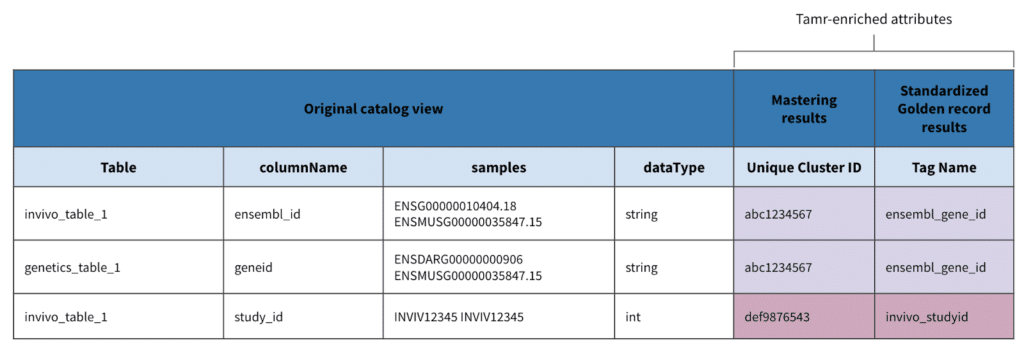
However, if a user manually reviews other metadata columns such as dataType and sample values, the user might be able to infer that (nvivo_table_1, enseble_id) is similar to (genetics_table1, geneid), and (invivo_table_1, study_id) is very different.
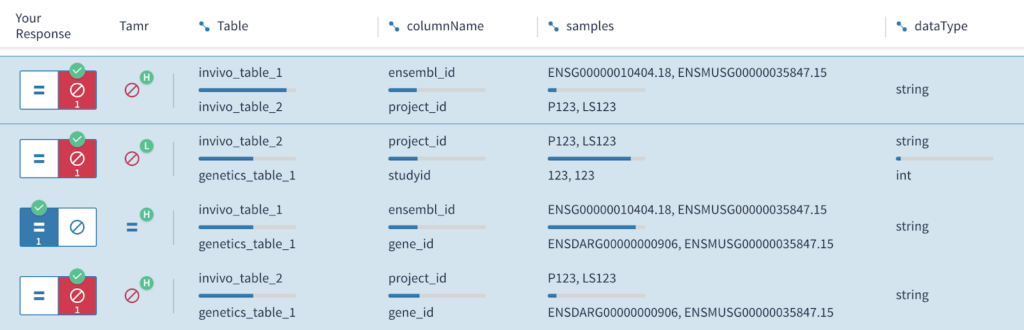
Tamr automates this manual approach into a machine learning model to group together similar attribute names based on the human understanding of how similar attribute metadata are from one attribute to another; this is illustrated in a sample of the Tamr model training interface shown below.
After attribute names are clustered together, Tamr can provide appropriate tagging for easy searchability such that the user can now search for “ensemble_gene_id”, for example, and capture all relevant data attributes across sources.
Clarity & Context – What does an attribute refer to?
Even if all users and data stewards become subject matter experts of the organizations wealth of data, having to manually review, tag, and maintain every dataset is not a sustainable or scalable approach.
Another advantage of having Tamr’s machine learning approach to group metadata attributes together is that attributes can be tagged in an automated and scalable way immediately whenever new datasets are added over time.
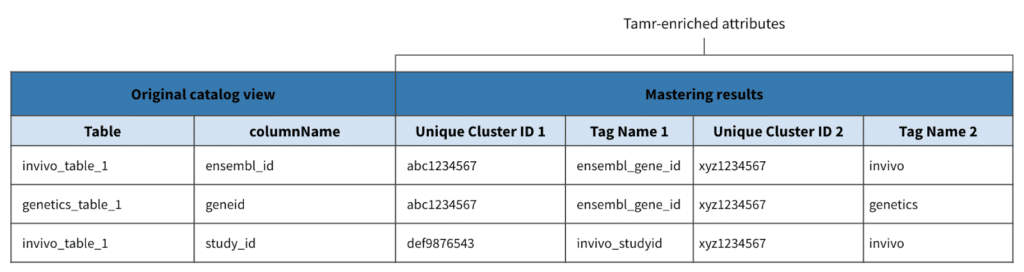
In the below example, Tamr processed the attributes study_id, geneid, and ensemble_id into distinct clusters that can be tagged by two different contexts. The first Tamr tag helps identify whether attributes refer to gene ids or study ids, while the second tag helps identify whether the table involves invivo or genetics research. Tamr’s approach to classifying metadata can help organize and maintain large volumes of datasets quickly.
Analytics – What actionable insights around my data can I generate?
Finally, with a feasible, scalable way to group, tag and categorize metadata, various types of operational and strategic analytics can be done to further digital transformation goals.
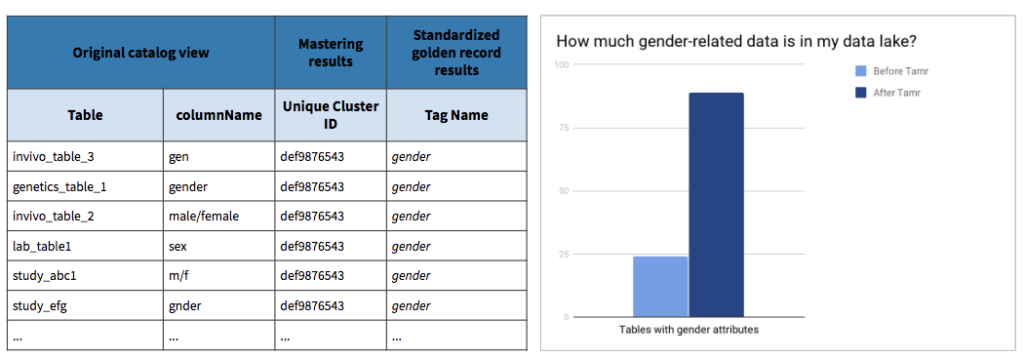
In a very simplistic example, trying to determine how many datasets exist within your organization contain data involving gender may not be straightforward without considerable knowledge of what you’re looking for. Searching and parsing catalog data for a simple answer is not obvious due to the variety of ways gender information can be represented or miss-spelled.
Using Tamr to generate standardized tags for analytics can help organizations better understand available data, as well as make actionable decisions on resolving any issues with data collection or usage.
Schema Discovery
As an extension of generating standardized tags for analytics through metadata enrichment, Tamr can be used to greatly simplify the naming of new data structures.
As we know, research data can be named very differently depending on the context of the project. In the below example, data tables were taken from two different research groups and it is unclear whether the data can be combined in a useful way. Using Tamr to link similar attribute names and metadata, it is possible to find attribute relationships across the two datasets and propose an example of what a unified view may look like.
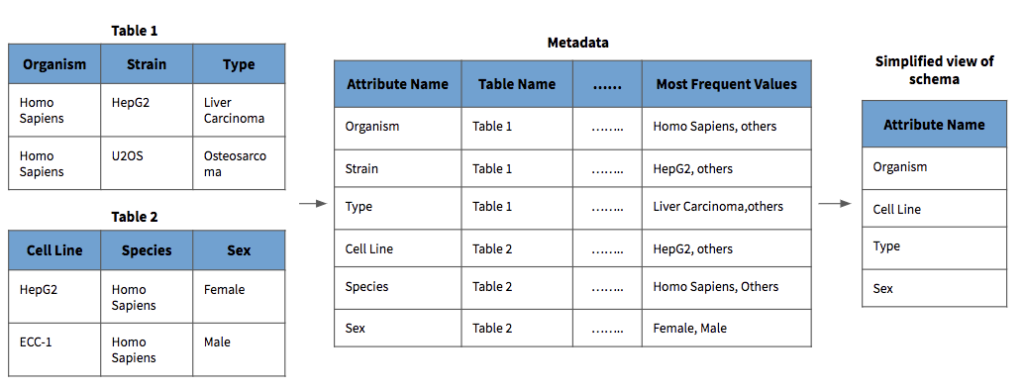
Schema Standardization for Data Integration
Finally, building on top of Tamr’s capability for metadata enrichment and schema discovery, Tamr can cluster common attributes names across disparate datasets to create golden record names of attributes standardizing data models. This built-in advantage is significant because it sets the foundation for downstream data integration and harmonization pipelines (whether using Tamr or other ETL software); in the past, this process would traditionally have taken weeks to months of data definitions and requirements gathering to prepare.
Below is a potential view in which Tamr helps build to support any data integration or data harmonization activity. For example, if we are seeking to search through the entire R&D data lake to analyze production data for invivo studies, we can probably pull all the data across different sources into one table to start investigating within hours.
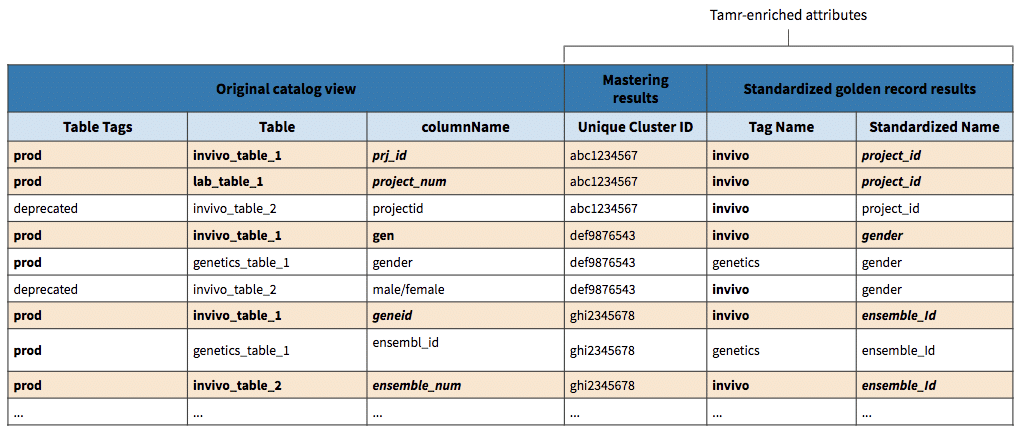
With such a view readily available, highly manual and mistake-prone activities such as building out entity relationship diagrams, mapping attributes, and auditing data lineage across large volumes of sources becomes much more manageable!
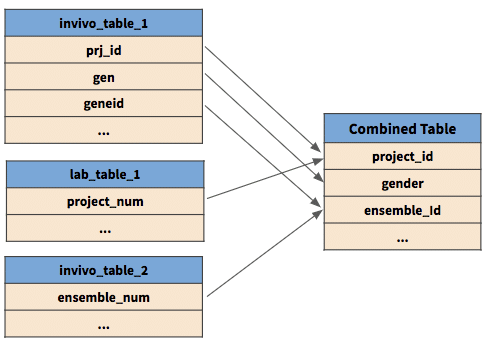
Conclusion
The traditional approach of manual metadata curation is inefficient and simply not sustainable for growing organizations with increasing volumes of decentralized datasets being generated over time. With Tamr, organizations can now finally leverage a true modern, agile approach in metadata management, and achieve significant acceleration to digital transformation initiatives in various ways from cataloging data assets to the actual integration of specific dataset records.
Get a free, no-obligation 30-minute demo of Tamr.
Discover how our AI-native MDM solution can help you master your data with ease!


