
Increase Searchability and Access in Data Catalogs and Metadata Repositories with Tamr Metadata Enrichment

With the intention of making data more FAIR (Findable, Accessible, Interoperable, Re-usable), organizations have invested a lot of time and money on software to identify and track datasets across existing data sources in the organization. Many software solutions promise a vision of systematically cataloging datasets in one place such that data consumers can always find and access the most trusted data available.
However, most data catalog solutions do not deliver at scale. Solutions that manage datasets rely on metadata describing those sources, and typically focus on the bare minima of enterprise data governance and stewardship, which limits the available metadata (the data about data) to describing dataset physical features (size, number of records, datatype, etc.), historic access, permissions and security settings, owners, users, etc. While users can infer meaning and the importance of various datasets based off of this information, it doesn’t actually provide context for what is inside the data and how users may want to use one or multiple datasets.
We have seen metadata management become difficult for data catalogs, metadata repositories, operational metadata stores, and any other collector of metadata as soon as the number of datasets hit a size where a team of data stewards can no longer manually curate all of them effectively. In our experience, this threshold is always hit sooner than expected, and the problem is compounded by the fact that historic data has been silo’ed across the enterprise – with current data stewards often having little or no experience with a significant fraction of the legacy data in an organization.
For some life science companies, data consumers may collectively need to sift through tens of thousands of datasets that can potentially have the data they need and it is not practical to limit their speed to R&D insights by attempting to impose process standardization on how every single person in the organization collects, uses, and shares data.
To make metadata management scaleable, Tamr users have leveraged Tamr’s agile mastering capabilities to enrich the metadata of their catalog views with attributes that give their datasets more meaning and searchability. Tamr does this by interrogating dataset record attributes to generate metadata that link how various attributes relate from one dataset to another, thereby generating standardized attribute metadata tags that span across all datasets.
Below is an example of how metadata may be portrayed in a catalog view, and how metadata enrichment can add to the view’s usability.
Applications of Tamr enriched metadata
Once an expansive data catalog or metadata repository is enriched with Tamr metadata, there is a plethora of opportunities that have been unlocked for further action.
This enriched metadata field enables a lot of possibilities, among them:
- Searchability: An example would be to identify all tables that may have a certain attribute easily
- Meaning and Context: Provide a readable attribute name to an otherwise obscure naming convention
- Schema discovery: Discover best practices and suggested naming conventions to organize your data based on what’s actually in it
- Metadata standardization: Be able to build analytics on top of your metadata to get better transparency across your data assets
- Preparation for data unification: With a standardized schema ready to go, trying to harmonized disparate datasets into a data lake would be a much more manageable process
- Enable intelligent row-level indexing: Scientists often want to focus their work on specific compounds, species, or genes. Knowing which columns hold this information across your entire catalog significantly help prioritize row-level indexing of these columns to better support their research
A future post will cover these applications and their added benefits in more detail.
Implementing metadata enrichment into a catalog environment
Many of our customers have existing systems in place to manage dataset metadata, and thus have taken a modular approach of implementing Tamr to quickly obtain value within their current data infrastructure in weeks rather than months. Below is a high level example of a simple dataflow and where Tamr’s metadata enrichment capabilities would fit.

The mechanics of deriving Tamr enriched metadata
The way in which Tamr tags metadata is anything but a black box. Rather, the generation of tags is produced by human-guided machine learning that greatly amplifies how much impact individual data stewards and subject matter experts can make in tracking tens of thousands of datasets.
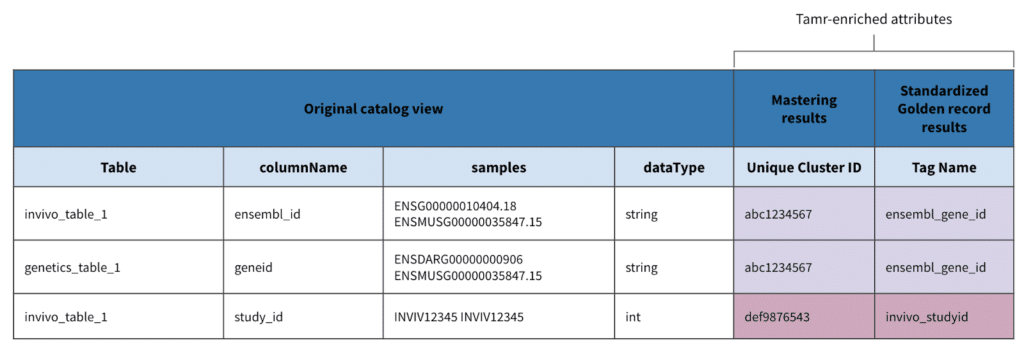
In the below example, metadata from several tables are brought together into a single view with a large variety of how attribute names are represented. As discussed earlier, a view like this doesn’t provide enough context or frame of reference without more intimate knowledge of each table.
Using Tamr agile data mastering to aggregate metadata into records and master attribute names, Tamr can group together different attributes across data tables and sources based on their metadata from attribute names, table sizes, value samples, data types, etc. to generate a new metadata field that stores a common naming convention for those attribute groupings.
In the below example, two raw tables are combined into one unified dataset for its metadata, and through Tamr, standardized attributes are generated for reference.

Conclusion
Tamr agile data mastering has been applied to metadata management by some of our customers to augment the gaps of their current metadata catalog and repository when the volume and variety of metadata is too large to manage manually.
Particularly in life science companies, where a large variety of data are used for different studies, functions, departments, and experiments, adding this component of metadata enrichment will be critical if they want to really achieve FAIR data and bring in every piece of R&D data into one place that people will actually use.
To learn more about the role of Tamr in enriching metadata to gain more control of your data, schedule a demo.
Get a free, no-obligation 30-minute demo of Tamr.
Discover how our AI-native MDM solution can help you master your data with ease!


