



A Data Scientist’s Rosetta Stone: Unifying Disparate Data with Ontologies

This post is a summary of my ODSC teaching course by the same name.
Data classification is the process of categorizing data points into a hierarchical and systematic structure called a taxonomy. Well-defined taxonomies are mutually exclusive and collectively exhaustive hierarchical categorization systems. Correct classification allows for identifying and measuring entities sharing similar characteristics.
The Challenge: Unifying Multiple Data Sets
Imagine you’re a data scientist. You have one dataset, which is classified into a taxonomy. You acquire a new dataset, of the same type of data but classified into a different taxonomy. Now you want to traverse the two datasets using one unified system of categorization to calculate, for example, how many records fall into a category across both datasets. You might consider just appending the two taxonomies into one “super” taxonomy, but this would leave you with category duplicates. Alternatively, you could map the lesser taxonomy into the better taxonomy category by category, but this method is time-consuming and begins to break down the hierarchical integrity of your taxonomies.
A better solution is to find a universal source of truth taxonomy in commonly understood industry vocabulary into which all other taxonomies can be mapped. One example of this is an ontology. Ontologies are frameworks for common industry vocabulary, and they include entity types, as well as both vertical relationships (hierarchical taxonomies) and horizontal relationships (cross-entity).

Ontologies as an industry-standard hierarchy of entities can serve as common ground between taxonomies into which each category can be mapped.
Proposed Solution: Algorithmic Mapping
We will walk through an example using this method of mapping into an ontology using two datasets of books and their genre classifications. The first dataset is one of Amazon reviews filtered to only the books and includes a structured taxonomy of genres. The second is one of Goodreads books with genres added via the OpenLibrary API using their ISBN numbers. These will be mapped into the Canadian Writing Research Collaboratory Genre Ontology (CWRC), which includes a tiered genre taxonomy.
In theory, one could manually perform the mapping of categories into the ontology, but the scale of the taxonomies makes this unfeasibly time-consuming. It would be best to develop an algorithm to automatically perform this mapping exercise that could be maintained over time as new data points and categories are added to our data repository. This algorithm should consider all matches, or places in the ontology where a dataset category could be mapped, and choose the best match based on semantic similarity.

An algorithm can compare all sets of pairs between a taxonomy and the ontology and determine which is the most semantically similar.
Aligning Taxonomies
In order to build an algorithm to map the taxonomies into an ontology, we needed a metric or set of metrics for measuring similarity between categories. Below are a few similarity metrics that we will calculate and compare for each pair of categories across the taxonomies and the ontology.
First, synonym similarity is a simple measure of the overlap between the synonyms of each word in the category titles. The rest of the metrics leverage Doc2Vec, which trains on a corpus of text and builds a model to vectorize documents that can be compared to one another with cosine similarity. We used a Doc2Vec model trained on the corpus of Wikipedia and vectorized different types of documents related to the genres for each metric. For example, the first Doc2Vec metric simply vectorizes the names of the genres, whereas other variations leverage the ontology genre definition and the subcategories under a top-tier taxonomy genre.

We calculated 5 different types of similarity scores, comparing the synonyms and contextual documents around each category.
We also needed an answer key of correct category mappings to which we could compare the results of our various similarity metrics. We built a set of pairs of each Amazon and GoodReads categories with their most accurate ontology genre match, aligning a set small enough to be manageable but large enough to be generalized.
Finally, in order to determine which metrics perform best, we will choose a subset of categories and compare each metric’s ability to predict the answer key. Below is an example: we’ve plotted the various metrics in different combinations to determine which two might be indicative of the correct answer. From this Literature & Fiction example, you can see that the first plot of Doc2Vec name similarity vs. Doc2Vec subcategory similarity gives the best indication of the true match, a trend that was consistent across the datasets.

Plotting one Amazon category’s ontology match possibilities versus the “correct answer” allowed me to compare the similarity metrics’ accuracy.
When we plot those same two metrics across several Amazon categories, we see two distinct sets of trends, one for those with a low name similarity and one for those with a high name similarity. This distinction suggests that for those Amazon and ontology category pairs which have very dissimilar names, context (subcategories under the Amazon top tier category) is essential for determining matches, while if the names are similar, the context doesn’t matter as much.

Amazon categories were most accurately predicted by subcategory similarity when genre names were dissimilar and by a combination of metrics at higher name similarity.
We followed the same metric comparison strategy for the GoodReads dataset, and found that two metrics (Doc2Vec names similarity and Doc2Vec names and definitions similarity) combined in one universal trend such that an increase in both combined indicates stronger category similarity.

GoodReads categories had a relatively consistent trend, such that higher name and definition similarity predicted better semantic matches.
Each dataset’s matching algorithm required the semantic similarity of both the names and a source of context around the genre name, and so those were the metrics we used to score each pair of category matches, determine a best match with the highest combined score, and align each book record to its corresponding ontology category.
Assessing the Results
In order to visualize the final results, we can ingest the datasets into Neo4j Desktop, a free and open-source graph database. We ingest each book record as a node and link it to its original category, which we link to that category’s ontology match. Then, in order to judge how our scoring algorithm did, we can look for two instances of the same book in the two original source datasets. Below is a diagram of the pattern which we will search our graph database.

In order to assess the accuracy of the algorithm, we searched for the above pattern in the Neo4j graph model, where a book was present in both datasets and got placed in the same ontology category.
Based on this pattern match, we are able to find two “Selected Poems” anthologies that existed in distinctly named source taxonomy categories but which have both ended up in the same ontology category.
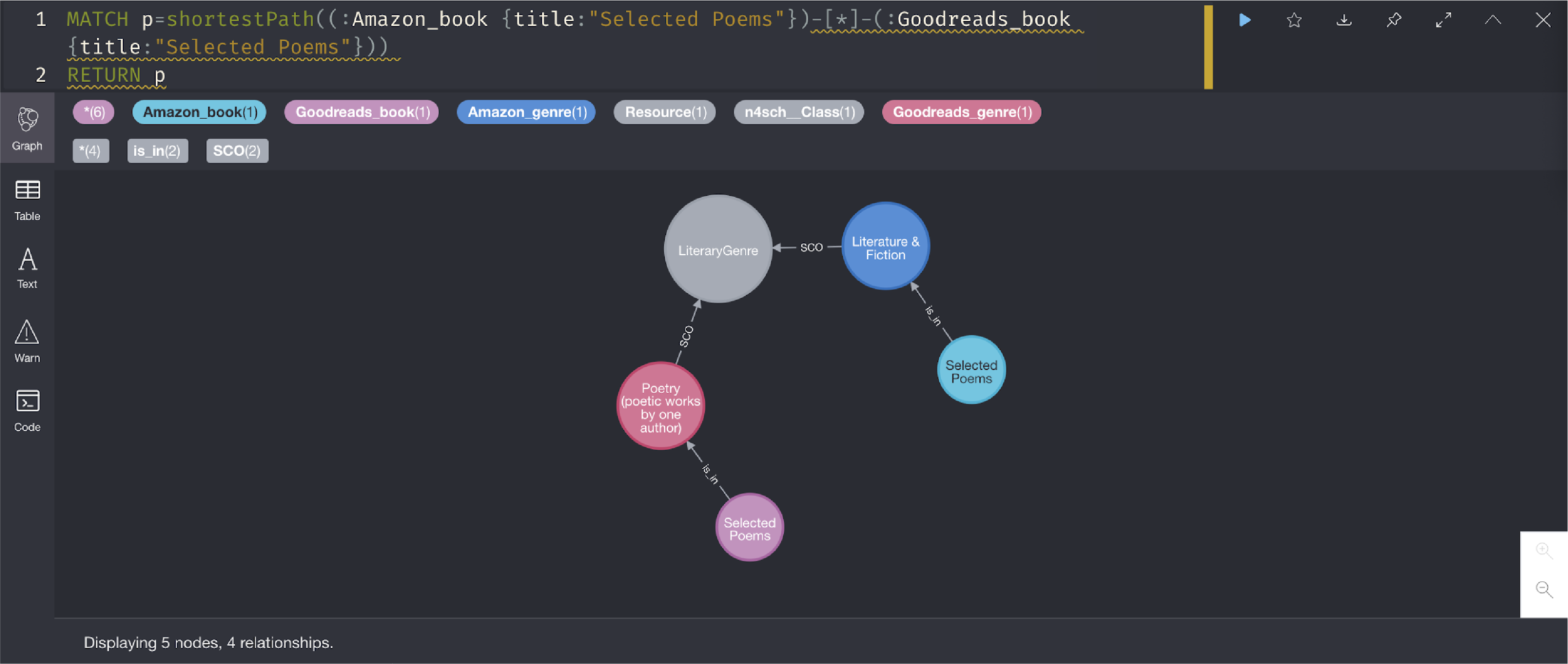
One example where we were able to find the accuracy pattern was with a collection of Selected Poems, which were both put in the Literary Genre.
Why Ontology Mapping Matters
This exercise demonstrates a few key points. First, automatic semantic matching is not a substitute for manual work, but rather can be used to augment manual effort and in efforts where the manual work required is too extensive. Second, the matching algorithm is only as good as the corpus the Doc2Vec model was trained on, and there were several categories such as “Feminist Genre” which on which the algorithm performed very poorly. These instances could be due to a lack of sufficient training corpus or inaccuracy of Wikipedia information on the subject.
Various other methods could be used to perform mapping or supplement this method, such as leveraging the Node2Vec functionality in Neo4j to use the books in a category as context for matching categories. More context could also be added to Doc2Vec documents with the reviews, descriptions, and titles of books in a given category. Finally, one could leverage a human-in-the-loop machine learning model to perform the classification of categories into an ontology with an enterprise-grade technology such as Tamr Classification.
Get a free, no-obligation 30-minute demo of Tamr.
Discover how our AI-native MDM solution can help you master your data with ease!


