
DataOps: Building A Next Generation Data Engineering Organization

Large enterprises are experiencing a foundational shift in how they view their data and structure their data engineering teams. As organizations capture more data than ever before, and store it in an ever-increasing variety of data stores, the prospect of competing on analytics becomes more tantalizing than ever. The challenges of using data at scale, however, is rooted in the “data debt” accumulated over time by enterprises struggling to manage the extreme volume and variety of their data. Paying down this data debt is the proverbial long pole in the tent for competing on analytics.
If you ask most employees, they likely believe their company’s data is neatly organized and easily accessible. As enterprise data professionals know, the reality is that a typical data environment resembles a “random data salad.” For decades, companies have been idiosyncratically deploying systems for business process automation, with the data generated from these deployments treated mainly as “exhaust” to the business processes. The resulting data environment is deeply fragmented and virtually impossible to integrate at scale — crushing the hopes of companies that want to develop an analytical advantage.
Indeed, even basic questions about the business, like “Who are my customers?” can’t be answered consistently and completely. The realities of doing business, like merger and acquisitions, further complicate data management. Companies need to start managing their data as an asset, much like they would their own money, if they hope to compete on analytics. It’s time to rethink priorities and start putting the “data horse in front of the analytics cart.”
Legacy Approaches to Data Engineering Are Failing
Legacy approaches to data management, such as ETL and MDM, are acceptable tools for small-scale or static environments; however, their rules-based approach can’t handle a large-scale, highly dynamic data environment (see this whitepaper by my co-founder Mike Stonebraker). Each question asked from the business would result in a long, complicated process of acquiring and manually preparing the data for consumption — providing little repeatability or scalability. Standardization is another approach that isn’t practical for large enterprises. Forcing top-down naming conventions for customers, suppliers, or other entities is hard to monitor and harder still to enforce. These complicated data management challenges are the reasons why we see such a high failure rate of so many potentially game-changing analytic projects.
Data Operations (DataOps) As An Engineering Methodology
We envision a world where enterprise data customers have ready access to high-quality, cross-silo, unified enterprise data for all of their core logical entities. Data Operations (DataOps) is a methodology consisting of people, processes, tools, and services for enterprises to rapidly, repeatedly, and reliably deliver production-ready data from the vast array of enterprise data sources.
DataOps was inspired by the concept of DevOps, a term pioneered decades ago by internet startups to describe one of the main ways they were trying to beat their much better-resourced established competitors . The concept is that the best way to increase velocity of new features being delivered in software is by using a continuous build, test, and release process that has a strong emphasis on QA automation. If you’re Google working on Maps, a sustained faster build, test, and release cycle creates a competitive advantage over Yahoo!.
Similarly, enterprises expecting compete on the basis of analytics need to empower analysts with easy access to up-to-date, unified data organized logically for them. Only by implementing an integrated, repeatable, scalable data curation process is it possible for a business to achieve the analytic velocity necessary to create a competitive advantage.
DataOps Capabilities & Principles
DataOps methodologies promote rapid, logical organization of all enterprise data, consumable downstream by a wide variety of methods. Its capabilities and principles are built for data engineering organizations that need to manage an architecture of constant change in data sources and uses.
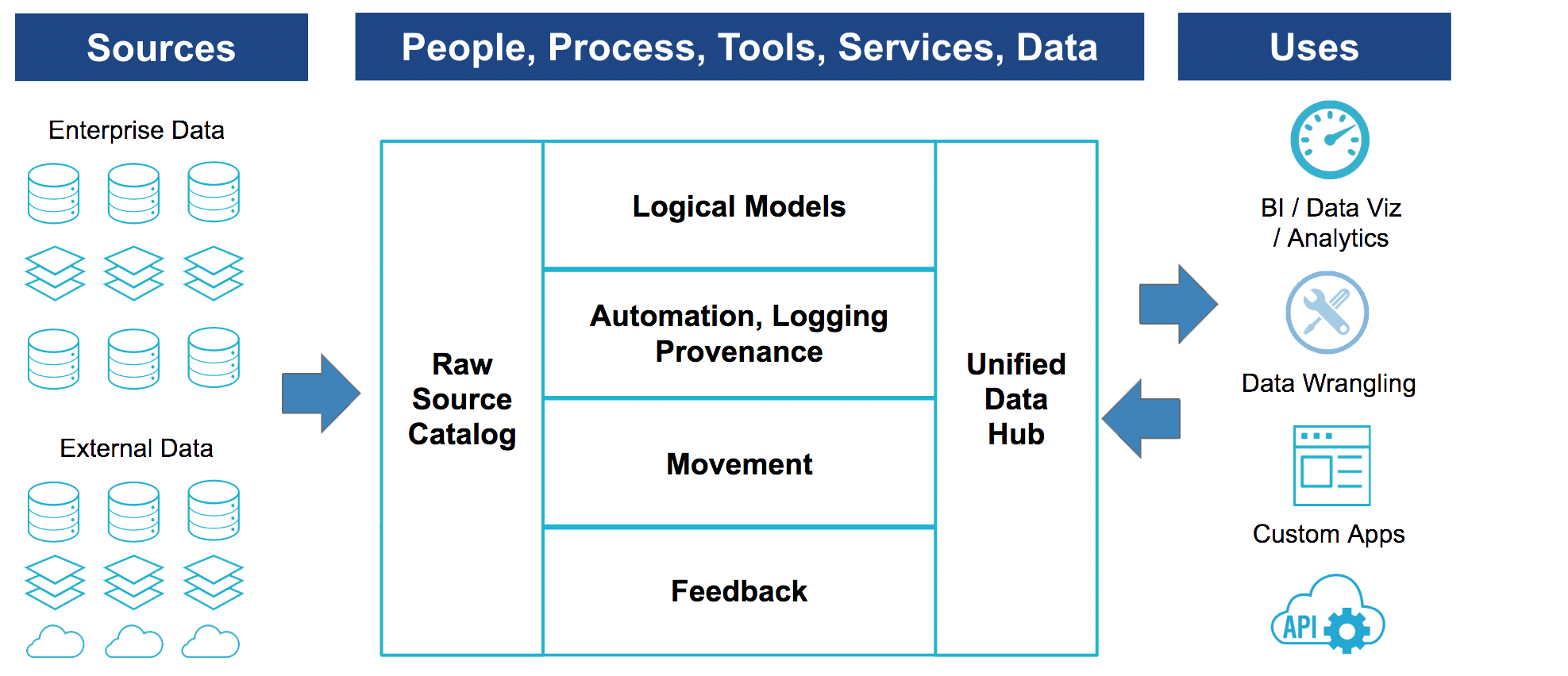
Figure 1. Open “DataOps” Ecosystem : Catalogs and Hubs
Capabilities
DataOps teams need to consider the following capabilities (See Figure 1.):
- Raw Source Catalog — Catalog all critical data sources, including raw physical attributes and records from the operational sources across an enterprise. Before you serve up insight, you need to know what you have.
- Movement / Logging / Provenance — These capabilities are required to move the data efficiently from Point A to Point B. Today’s ETL platforms, having been refined and hardened over the past two decades, offer highly optimized movement and manipulation of data. Core features, such as end-to-end data lineage and dependency analysis, as well as data quality and operational metadata capture, make your raw data sources and feeds highly accessible and reliable.
- Logical Models — Well-designed logical models deliver on three fronts:
- Flexible Format: Fundamentally, a single logical entity can be completely described by a collection of simple key-value pairs. A flexible format must hold up to both RDBMS design and highly normalized document search engines.
- Abstract: The model must successfully abstract the many varied physical data sources and feeds. Consumers of data care about analyzing entities like customers, suppliers, products or purchases and not a collection of source attributes.
- Semantically Meaningful: A logical model speaks the language of the consumer, allowing them to understand the underlying physical data, consume it, and provide feedback.
- Unified Data Hub — An analytical system of record for key enterprise entities that is accessed and curated by any employee in an organization. Within the data hub, you gain a holistic view of your data landscape. This includes the entities that have been organized, the sources contributing to each entity, the applications utilizing the unified data, and the individuals who are curating and consuming the data.
- Feedback — Provide users with a feedback mechanism to identify where problems in the data exist. This will improve the upstream system dynamically and continuously as well as eliminate the need for consumers to go to people physically managing data to provide feedback or put in requests. Critically, feedback is enabled in the unified data hub in the language of the logical model.
These capabilities deliver clean, unified views of data organized in a way that consumers would want it — while respecting the extreme amount of variety in both sources and uses. Users can consume a much higher quality of data faster while eliminating the need to idiosyncratically prepare the data themselves.
Principles
The DataOps principles underpinning these capabilities are equally as important to consider. These principles don’t just apply to tools and technology, but also to people, process and services. DataOps is ultimately an ecosystem, and changing organizational behavior is just as important as altering technological choices.
- Interoperable: Open, Best-of-Breed, FOSS & Proprietary, Table In / Table Out — An ideal data engineering architecture should include technologies that are best-of-breed and open. Allowing mega-vendors “guided tours of your wallet” needs to be a thing of the past. Delivering clean, complete data to consumers when they want it and how they want it requires piecing together multiple technologies from different vendors, whether they be large tech companies or startups. Moreover, there can’t be an aversion to open source if it can best solve the problem. Technologies and processes need to interoperate and follow the basic premise that they should be able to easily accept a table in and produce a table out.
- Social: Bi-Directional, Collaborative, Extreme Distributed Curation — Consumers want to use a wide variety of tools to interact with their data. They want to visualize information in their favorite analytic tool or wiki page and provide feedback directly so physical interaction or request tickets aren’t necessary. The communication paradigm needs to shift: information flow shouldn’t always be from source to consumption. Rather it needs to be bi-directional. It’s equally important that source owners receive feedback from users as users receive data from source owners. Moreover, like the modern internet experience, this collaboration needs to be enterprise-wide. Users are continually being conditioned to be responsible for data curation in their personal lives and data engineering teams should leverage this.
- Modern: Hybrid, Service-Oriented, Scale-Out Architecture — Flexibility is critical for next-generation data engineering teams. When creating a repeatable architecture to service data consumers, ensure the backend has the capabilities to scale out as projects broaden in scope. Also, using a microservices-based architecture when developing key capabilities is critical, as changes often need to occur in some specific functionality and re-architecting the entire system isn’t desirable. Finally, make use of the cloud for scalability when needed but consider that a hybrid approach of cloud and on-premise capabilities is likely the way to go.
DataOps Wave Will Transform Data Engineering Environments
Applying a DataOps methodology to your data engineering organization will allow you to achieve transformational analytic outcomes and “capture low-hanging analytical fruit” that will save your company money and drive additional revenue. Quickly delivering clean data from the vast array of enterprise data sources to the vast array of consumption use cases in a repeatable manner will build your “company IQ.” DataOps is the transformational change data engineering teams have been waiting for to fulfill their aspirations of enabling their business to gain analytic advantage through the use of clean, complete, current data.


