
Achieving Customer 360 Nirvana

Tamr AI-Native MDM Demo

Struggling with fragmented data, the lack of a single trusted single view of your customers, and costly data mastering efforts? Join Tamr experts for a live demo of our AI-Native Master Data Management (MDM) platform, our integration with Salesforce via real-time APIs, and our MCP integration with leading LLMs.
In just 30 minutes, discover how to unify and master your customer data faster, better, and more cost effectively, and use that trusted data to power downstream systems and generative AI applications.
Learn from our expert speakers:

You’ll learn how Tamr:
- Provides intuitive B2B and B2C Customer 360 views with ready access to mastered, golden records
- Makes it easy to configure the platform and our data products for different use cases
- Supports real-time integration with operational systems like Salesforce and LLMs
- Surfaces valuable insights about your data and its quality

Struggling with fragmented data, the lack of a single trusted single view of your customers, and costly data mastering efforts? Join Tamr experts for a live demo of our AI-Native Master Data Management (MDM) platform, our integration with Salesforce via real-time APIs, and our MCP integration with leading LLMs.
In just 30 minutes, discover how to unify and master your customer data faster, better, and more cost effectively, and use that trusted data to power downstream systems and generative AI applications.
Learn from our expert speakers:
You’ll learn how Tamr:
- Provides intuitive B2B and B2C Customer 360 views with ready access to mastered, golden records
- Makes it easy to configure the platform and our data products for different use cases
- Supports real-time integration with operational systems like Salesforce and LLMs
- Surfaces valuable insights about your data and its quality
Watch Webinar!
Want to read the transcript? Dive right in.
Alright.
Good morning, good afternoon, or good evening, everyone, and thank you so much for joining today's session, achieving customer three sixty Nirvana, Tamer AI Native MDM live demo. Before we begin, I'd like to cover a few housekeeping items. Closed captioning is available. Simply hover over the virtual stage and click the CC button located at the bottom of your screen.
We encourage you to submit your questions and engage in the chat leveraging the q and a and chat tabs in the engagement panel on your right. And we'll do our best to answer questions at the end of the presentation, and if we are unable to get to your question, we'll follow-up with you directly.
We've also added some additional resources, which are available in the docs tab and the engagement panel on your right. There, you can find some additional related content. Today's webinar will be available on demand after we wrap up. It will be sent to you via email directly.
And lastly, as we head into the demo section of the program today, some of the content may be small or hard to read. To help, hover over the bottom of your screen to maximize your window to full screen, or you can leverage the plus and minus icons to zoom in or zoom out.
Our esteemed speakers for today's session are Ravi Halasi, head of strategic solutions, and Elliot Kim, senior sales engineer. Welcome to you both. Now over to you, Ravi.
Wonderful. Thank you, Tara. So in today's session, we're going to give an overview of Tamer's solution and how it overcomes the problems prevalent in the MDM industry.
We'll give you a demo of Tamer in action. You can see it for yourself and wrap up with some advice and guidance on how to get started with Tamer.
So a little bit about Tamer. We believe the MDM space is truly ready for change, and that's what we're bringing to the market. We are the only true AI native enterprise MDM player in the space, and we've adopted this approach since the very beginning.
Tame was born out of MIT with a Turing Award winning founder, and we disrupt the market because we've automated so many of the monotonous data cleansing and data management tasks that others have experienced with a painful perspective from MDM in the past. Tame is a market proven solution with eighteen patents for our approach deployed across multiple industries with a number of different use cases. And regardless of the scale of your data, both in terms of volume and sources, MDM doesn't have to be a big scary problem anymore. Because we use AI at the core of a product, you can take away those many months of building, setting up, and maintaining rules, which have limited effect.
One of the key benefits of Tamer is the rapid time to value as a SaaS solution. And you can run your first data flow on day one because there's an out of the box workflow using a pretrained machine learning model and best practice enrichment and data quality improvements.
Because we use machine learning at the heart of the engine, we can achieve a much higher accuracy, and we also use third party data to provide additional verifications.
So regardless of whether you're using an analytical or operational use case for your first MDM steps, we have a much lower total cost of ownership than other solutions because you don't need a ton of professional services to get things up and running.
So why do we think the MDM space is ready for change? Well, let's take a look at what most people do to solve the master data manage management problems they have, and doing nothing's not really an option given the amount of data in an organization is constantly growing. So first option is to add more people.
And so a lot of companies will try and build a data management solution themselves with a homegrown set of toolkits and maybe some libraries and throw more people out of problem. And this can be successful at first if you have low volumes of data and there's not much variety in your sources. But at some point, this becomes very difficult to manage. You have limited functionality, and it's difficult to bring in external data or use the data in an operational manner.
And so with this approach, you end up building a custom piece of software to solve this problem, which you then have to support and maintain going forward, which is an additional effort and cost. So, really, you should hire a software company to solve this problem for you.
The second approach we see is people add more process, and this is where you deploy more traditional legacy MDM platform that's often rules based. This approach is very high in terms of governance and policy setup and management, so it becomes very costly and complex to maintain going forward. It requires a lot of resources to customize, and you could spend six months to a year just to get started.
Many times, customers come to us because they're not happy with this approach and the results it gives, and it's taken them upwards of a million dollars or more to find out.
Final approach is to add more productivity with Tamer, and this is where we use our proven AI to address the scale of a problem and lower costs and improve outcomes. This approach is all about getting to the outcome of trustworthy golden records in a way that's never been available before in a shorter amount of time.
As a SaaS solution, we simply connect to your data warehouse, data lake, or other cloud object store. If you've got other sources, you can such as CRMs or ERPs, you can land data to these areas from which we'll read your data, clean it, and create golden records ready to be published back. Or you can use our APIs and consume it through other applications or systems, making use of Tamer's webhooks for real time notifications.
It's important to appreciate the real impact Tamer has had to our customers because a data master is only as valuable as the outcomes it drives, and we've delivered many very many impactful outcomes since we came to market in twenty thirteen.
Many customers see an immediate impact by driving new revenue, whether that's through improved outreach or enhanced customer segmentation achieved by creating a unified view of a customer across multiple sources.
Companies want to answer the question, what am I purchasing and who from? So Tamer also provides visibility into billions of dollars of annual spend across organizations.
Many organizations have different subsidiaries with different locations and operating units. So using external reference data from public and licensed data providers, including key partners like Dun and Bradstreet, can really help make this more impactful.
This increased transparency directly translates into reduced spend and cost savings.
And finally, customers have been able to realize spend reductions by rationalizing their infrastructure for master data and decommissioning redundant or legacy systems.
In today's demo, we'll focus on our primary domains of companies and people. And, of course, within each of these domains, there are plenty of nuances about how data is cleansed, matched, and enriched. Regardless, Tamer has you covered. So now over to Elliot to show you Tamer in action.
Appreciate it, Ravi. Ravi, if you stop sharing your screen, I can go ahead and share mine.
Certainly.
Okay. Hello, everyone. In today's demo, I'll be covering the journey of how Tamr can provide all the steps you need to be as efficient as possible and AI ready.
Let's jump right in.
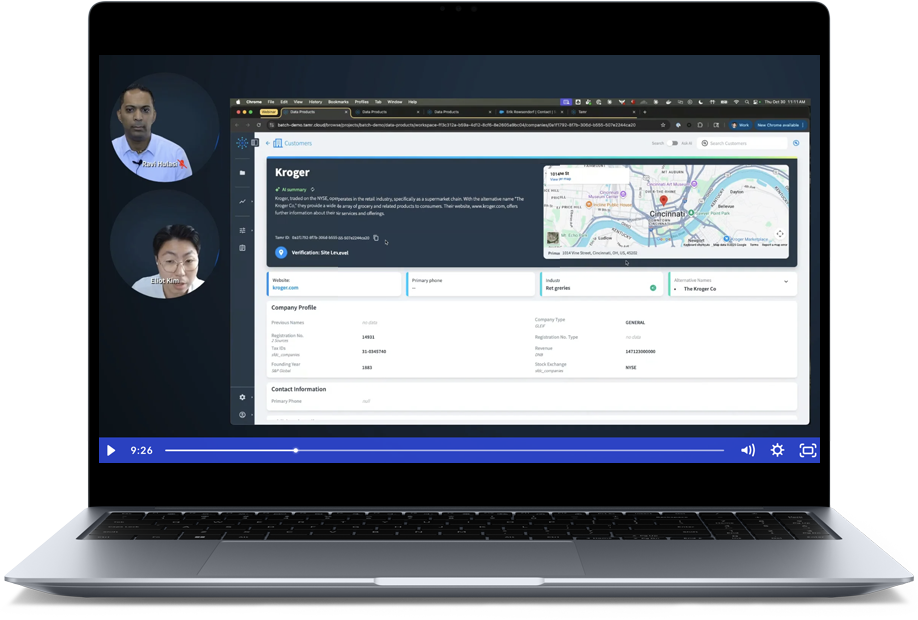
So to start off, we're looking at a golden record of a business or organization.
This is a place where you can find a consolidated accurate view of an organization or company, so Kroger in this case, across all your sources right at your fingertips.
As you can guess, this is gonna save you a ton of time because now there's no longer a need to search amongst all your different sources, doubt whether your information is accurate or complete, and allows you to make more of those data driven decisions.
Instead of having to write and manage these rules manually, Tamer's AI is behind the scenes automatically clustering records from all your different sources and then cherry picking the highest quality values and then providing a reliable record that can be viewed and then published anywhere you like.
Tamer will actually take it a step further in a couple different ways. The first one is what we call verified match. So verified match essentially uses Tamer's internal and proprietary records to improve clustering confidence and verify and make sure that a company is legitimate.
Then on top of that, Tamr will standardize fields like website and address. Tamr actually reaches out automatically to Google to ensure that your addresses are complete, standardized, and consistent across all your records.
Something to note here is this Tamer ID up top. So as you can imagine, this is a unique ID that's associated with every golden record, But more importantly, it's associated with every record that's a part of this golden record. So why is this important, you ask? Because when you end up publishing this data to your different sources or other cloud storages, you now still have a common field or point of reference to still be able to associate all the records that Tamer brought together automatically even outside the context of this UI.
Of course, you have the information to see exactly what tamer clustered together across all your different sources, how many records were brought together, and the exact values from each of those records.
Rather than having to write rules and manage different variations such as misentered information or even missing data or missing values, Tamer will handle that automatically for you as well.
And, of course, this applies to enrichment as well. As you can see, Tamr has partnerships with enrichment services like DNB to seamlessly and automatically leverage your reliable and existing enrichment sources to your golden records without any additional configuration.
So, Elliot, can you talk a little bit about how that enrichment with Dun and Bradstreet works? Does the customer provide data? Is it is it included as part of the table workflow?
Yeah. Great question. So if you are a subscriber to D and B, all you have to do is provide us your key, and we will handle everything there for you. Because we are not a data provider, you want people to see the enrichment data, like, from D and B. If you're not a subscriber, we can still benefit it from, like, in hierarchies that I'll actually touch upon next.
Great.
So continuing that theme of automation, Tamer will automatically create a hierarchy with the records that you have to help you understand how one organization relates to others. So whether you have any enrichment services or not, because this is only using the records you have I actually like to show the example of Kroger because you understand how your white space is. Right? So in this case, Kroger rolls up to some global ultimate parent that isn't in your records. But once you obtain that record, it'll automatically populate that help populate that for you and help you understand the context of where you're missing your data and give you a better understanding of how your organization that you're looking at relates to others as well.
Now that we understand how Tamr visualizes an organization, let's see how that changes for a person.
So while this page looks familiar, the attributes for people, of course, are gonna be different for the attributes for organizations.
However, what is similar is the rich and actionable information they can all see in one place.
Relationships can be created and configured with APIs and easily be able to associate very similar to what you saw in organizations and be able to easily associate one people from another with, your given business rules. And on top of that, Timur will actually suggest potential related customers for you for for you to verify or even identify as potential duplicates from a curation perspective as well.
So, Elliot, one question there. So you've shown how Tamer suggests relationships. Presumably, if the customer has those relationships already defined, that's something that can be imported as well.
Absolutely. Yeah.
So now that we understand how Tamr cluster automatically and visualizes them, let's take a look at how seamlessly Tamr can integrate with other applications like Salesforce and how a real time change affects a golden record.
So looking at Eric Rosendorf here, let's note his current job title.
And if I were to go ahead and switch into Salesforce and if with someone with the right permissions, be able to modify this and reflect a change in position or title from Eric Rosendorf, and go ahead and save that change.
This change is now saved, and it should be immediately reflected in the golden record.
During API call, that can easily be seen in the three sixty page in real time.
And so, Ravi, you've shown me for Salesforce, they are sort of the promotion for Eric Rosenthal. Presumably, this could be a similar pattern for other applications, maybe something like a Workday or PeopleSoft or or any other enterprise application.
Yeah. Of course. This would work exactly the same as with other applications to communicate bidirectionally with APIs or webhooks to take actions like updates that you just saw, search before create, merge, and others that you can find extensively in our documentation.
Great.
Okay. So now that we've had the option to update and see everything in real time and make sure that I have the most up to date and accurate information, let's say that I now want to have some resources to continue the next step to ensure that my data will be AI ready. Tamer's Curator Hub allows you to do exactly that. Data curators can now come in here and actively merge, unmerge, and see the information or task that they need to readily handle. So for instance, we can see that there are a suggested duplicate of a particular person.
I'm now able to have full control of being able to select which record survives or even more detail which attribute from each particular record survives and goes into the merged record.
So, Penny, I've seen you've shown how curation takes place here and the integration with enterprise applications. And both of those are very impactful, especially those who are starting off on their MDM experience.
But we're also seeing more and more customers now looking to make their data ready for AI initiatives and having better, information going in to those applications, particular LLMs. Can you talk a bit about how the data from Tamer can be consumed by an LLM?
Yeah. Absolutely. So just like we saw in the integrations with applications and how seamless that can be in terms of how it communicates, this same concept can be applied to integrating with Pagentic interfaces. Right? And to that point, let's actually go ahead and see that in action with Claude.
So now we're assuming that, you know, our AI is now our our data is now AI ready.
Let's operationalize this data to a scenario where a user can actually interact with this data through an AI agent like Claude by integrating with Tamer's MCP server. So in today's story, let's assume that I've just come back from a conference, and I've met someone named Robert Soley. I'm gonna go ahead and ask in a simple prompt.
And now Cloud is able to communicate with Tamer to find an existing golden record and easily be able to pull that up here. So it sounds like it was able to pull that record up. It hyperlinks it to be able to bring that record in and easily see the information here.
So now that we found Robert, you're able to easily interact with this system. You're able to ask it whether or not you need to find some information associated, whether that's asking for them to potentially find a coffee shop nearby or even be able to take action on this as well. If you wanted to interact and actually update it, not only can you search and extrapolate the data, you can update information. You can create your data all through the familiar prompting action here.
So if you wanted to make a change and say you wanted to update some sort of phone number, let's say that while you met Robert during the conference, you found out that he got a recent promotion or he gave you a business card and realized that the phone number was incorrect or different, you're easily able to ask Claude and use the agentic AI interface to be able to communicate then, ask them to simply change in a secure way, in a very friendly way, and that way it's more efficient, and then you can have a lot of access into what it would be like if your data would be AI ready.
And, of course, just like before, any changes that you reflected here, you can imagine how it would change in real time in that three sixty view before. So in today's demo, you were able to see, start to finish, on how Teamwork visualizes and exposes important information in a golden record, how Teamwork provides the tools to curate and understand your data, and lastly, show you really the foundation of behind guiding you through that MDM journey ensure that your data is very reliable and there when you need it the most.
Appreciate it. Thank you. And, Ravi, I will hand it back to you.
Wonderful. Thank you, Elliot. So I think that's that's that's quite impactful. You've seen how data's gone from building out those three sixty views all the way through to consuming them, enriching them, curating them, and then making that data available for enterprise applications, whether that is a Salesforce source of application and then also interacting with large language models.
I saw one question came up from Mark about what AI agents do you support. And, certainly, Tame has been designed with open APIs, and we actually build out against the MCP protocol. So, certainly, any AI agent which is communicated in that way can register Tamer as another service for master data. So happy to follow-up and talk a bit more about Copilot afterwards.
But certainly, in terms of what you've seen, as as you saw, why Tamer? Well, we deliver results that really are faster, cheaper, and better. And key to enabling this is our approach to matching, which is patented and allows us to have the ability to process large volumes of data efficiently with superior results when compared to other approaches.
It allows you to become production ready in a number of weeks with minimal resources required to run and maintain the solution. As you've seen, the real time APIs allow you to provide that operational access to clean data across your enterprise regardless of where that data lies or how it's being interacted with it. As you saw, the three sixty interface is very intuitive as well as the curation workflows that allow you to focus on data which needs that further attention. And so a second question came up as well regarding curation and the question of how many records go through into curation, and that can be based upon a number of different thresholds.
The belief at TAMA and the approach is that the machine should do the heavy lifting, but there'll always be a few outliers. Whether those are outliers that can be resolved by specific business rules, tailored to your organization, say, five percent or so, or the outliers of, say, five percent of the data which may need some extra eyes on it. So within Taimer, you can actually define different curation cues based on different thresholds or areas of concern and route them to the appropriate curator with the area of expertise. So we do allow for that customization because, obviously, every enterprise has their own focus on data and how it should be managed. So regardless of whether you're starting out on your MDM journey or you have a system in place that isn't meeting your needs, we can help get you to that better outcome of better quality data.
And based on our collective experience working with all those customers on implementing MDM or indeed improving the MDM experience that they currently have, we've defined this journey to success, the MDM journey, and it really focuses on ensuring that you have data that you trust and getting it into the hands of those who use it and avoids the common pitfall we see with MDM approaches in that people focus on technology without involving those who actually know the data and use it most. So this journey to successful MDM outcome really starts by understanding the problem that you're trying to solve, then going forward and improving the data, prioritizing the high quality data in line with your business goals, whether it's better analytics, operational excellence, or creating AI ready data.
To do this, ask simple but crucial questions about your master data, such as, do you know how many customers you have, and does everyone agree with that number?
As you can appreciate, if you enter that into an AI agent, you may get a different result before Tamer than if you have, an analytic that's also reading data before Tamer as well. So having Tamer out of the middle producing a consistent answer is imperative to data consistency across the enterprise.
And so using Tamer and its AI approach to improve data quality and integrity helps provide significant benefits over traditional rules based MDM by allowing you to scale data, embrace them with human feedback, and enrichment data with external and, other varying sources as well that could be quite dynamic in nature. And so before you go ahead and connect your master data to those operational systems, get feedback from multiple data consumers across departments, including both data teams and end users, so everyone's in agreement that data is indeed fit for purpose.
Taking this approach gets you to a better outcome in a shorter amount of time.
And so thank you for your time today. As we've shown you how Tamer is a superior master data solution, we'd love to show you what we can do with your data. So check out this link on the left to schedule your own custom demo where you can look at the results and scorecards prepared with your data in Tamer. And whether you're just starting out on your master data journey or are already along the path, check out our ebook link on the right with lots of practical advice on how to be successful.
So thanks for attending. I wish you happy mastering. And now back to Kara.
Yeah. Thank you so much, Ravi and Elliot. If you'd like to stay on, we're going to shift into a live q and a. So if you haven't already, feel free to submit your questions using the q and a box on your screen, and we already have quite a few. So the first one, how does Teamwork protect my data from going out? Do you install within my network?
So I we as a SaaS solution, Tamer is reading data from your stores, whether they're internal systems or or external ones. We have extensive security guardrails and privacy frameworks to ensure that data is not going out to any other parties.
So as as we've been deployed and set up, we have various controls available to deploy into different geographic regions to ensure that we are compliant with those privacy frameworks. So, essentially, the flow is read data from from your systems into the tenant that we provision exclusively for you, process it, publish it back out.
Great. Thank you. Next up from George, can we get the parent record from Tamr even if we don't have it in our database?
If you're referring to the parent record in the hierarchy example that I showed you, so it'll be very similar to the example that I showed you with Kroger where if it rolls up to a global parent and it's not in your record, it'll just show up as an unmatched reference record. And because we're not a data provider, we can't give you that information if you don't have it within your database. That being said, if you already have or eventually acquire that information or acquire that record, it'll automatically populate in that hierarchy, and you're able to view it from there. Or you can take advantage of the relationships I mentioned earlier to establish some sort of custom logic between records to establish a parent child relationship that way as well.
Great. Next up from Andy, does the verified match feature work for confirming company data if not a D and B subscriber?
Robbie, would you like to take this one? Sorry.
Sorry. I I didn't quite catch that. Can you repeat that, please?
Yeah. That that one didn't hear.
Does the verified match feature work for confirming company data if not a D and B subscriber?
Yeah. So tame of verified match works across a corpus of larger data, not just Dun and Bradstreet. So it's about five hundred million company records overall coming from multiple sources, not not just necessarily a license through Dun and Bradstreet. So we have customers who are using Tamer verified match who are not currently subscribing to Dun and Bradstreet. So answer is yes.
Lovely. Thank you. This next question is a two part question. So the first part, how do you customize your Symantec data model for the customer to add additional fields? And then secondly, do you support custom hierarchies for FinServ outside of legal hierarchy, for example, potential risk or credit hierarchies?
Yeah. So that's a common question we get, Mark. So, yeah, we've we've focused primarily on commercial hierarchies, but certainly depending on the data provider, if those hierarchies are are available, say, through Dun and Bradstreet or another provider, those can be integrated as well. Certainly, when it comes to customizing the semantic model, so we start with an out of box workflow, their availability to customize that both in terms of types of fields that are used within there, as well as how they match as well. So, certainly, there there are different levers that can be pulled to to provide those sorts of customizations too.
Great. Thank you.
Another one from George. What if we have hundreds of thousands of duplicates? Will curation happen automatically, or should we go in each record and select which one we want to keep?
Yeah. Good question, George.
Blake, go ahead.
Yeah. Yeah. That was yeah. Saw George's question a bit earlier. Yeah. After Elliot's demo. So, yeah, that's the curation queue that I mentioned and the ability to customize what's being used there.
So the general approach and belief with Tamer is that have a machine do, say, ninety percent of the matching from there. If you got business rules specific to your your data, sure, apply those. Probably takes another five percent of the data challenge, and that leaves that remaining five percent, which can go to those curation queues. So even if you have very large points of data, the vast majority of it is being matched by the existing workflow.
And from there, you can have that curation queue set up, multiple queues for different people with various levels of focus or expertise to go through and attend to those records. The goal isn't for everything to be sent through to a manual curation workflow. Certainly, that could be an approach, but it can be quite intensive in terms of human capital. The idea instead is focus the humans on the records, which are the edge cases will have specific problems to solve.
Great. We have plenty more questions to go. So another one, this one's from Chris. What is the MDM framework? How do we create MDM tags? What is the recommended process for developing MDM framework?
So the framework there, ask the short answer. Please download the ebooks. Talks down down the framework in more detail. But, certainly, I think the recommended process involved there is to really understand what is it you're trying to solve and what's the business outcome you're looking for.
And that sounds that sounds certainly very very remedial, but at the same time, we're seeing folks who just go and deploy technology, spend so much time building out rules, and and are concerned about, let's say, the structure of the data and where it's moved, but aren't giving an output that's really that useful for those consuming data. So that's why you'll see the approach that you'll in the ebook is really to look at how's the data being consumed, who's consuming it, what is it they're looking for, and is the data and the MDM approach following that itself. And that that applies whether you regardless of the type of MDM deployment style that you're looking for as well, whether it's analytics go all the way through to central MDM.
So key point of the framework is focus on the business outcome, not just technology.
Lovely. From Margie, how do you compare traditional fuzzy matching to your AI based matching? Any pros and cons?
Yeah. Certainly. I think in in what we've seen with traditional fuzzy based matching, it's very much focused, let's say, on a a short distance based comparison upon upon a particular field. Where I'd say the advantage is is is really twofold.
Firstly, being able to have that semantic understanding of records, whether that is even looking at an address or a company name, and understanding the ways in which records can be represented that go beyond just writing simple rules. So in, essentially, you're looking at text embeddings and vectors to understand, for example, a capital funding trust and the way in which it's represented could be two different ways. So more than just string similarity in that respect. Secondly, the approach we take to optimize the processing of it is one of those patents that I mentioned, and that allows us to really run at scale.
So a fuzzy matching logic routine may not be able to scale at large volumes of data. So really, it's both understanding the context, which is more detailed, more nuanced, and then be able to do that at a larger volume of scale. I think those are the two advantages we've seen compared to using existing fuzzy matching algorithms.
Great. Thank you.
We have four wonderful questions from Kushal. Hopefully, I pronounced your name right. The first one is, how does Tamer detect incremental changes, for instance, updated patient or provider records and avoid full reloads?
So Ellie and I were talking about this the other day. So there's there's a couple of ways. Does does the application does the source application itself support any sort of notification? Great.
If it does, fantastic. We'll just take that notification, usually a webhook or so, push that through and run it. But that's not always the case. So often, we see the scenario where folks just have a table or an application, here's some data, go process it.
And so, essentially, what we do is a scan of that table to identify ourselves what the incremental changes are. If the application can't provide us with those incremental changes, we have to determine that.
It doesn't mean it's going to be a full reload, as you mentioned, though. There's actually a very efficient scan that we do to look at the data, whether it's looking at primary keys, whether it's looking at the entirety of a record to see what's changed. From there, let's say we've got a large volume of data, let's say, a million records or so, it may be only ten percent of that data has changed. So we'll do a scan, identify that ten percent, and then process just those updates.
So in that way, we're not running through the entire million record dates again. We're only processing the hundred thousand or so where there is actually change itself. So depending upon the application, you can if it can send out just the changes itself, great. We'll take those.
If it can't, we'll do some investigations on the data and automatically process just for records which have changed.
Does Tamer's user interface support full stewardship operations such as add, update, delete, undelete, merge, unmerge, link, and unlink records?
So the interface in terms of operations, you've seen that I showed you the curator hub. So it allows you to merge, unmerge, suggest edits, and actually update your data as well. We've limited to those actions because we wanted to actually limit and control and go have the proper governance in terms of who has access to the ability to change that kind of information. So when it comes to more of the creation, deletion, and the creating of the relationships, we suggested doing via API outside the the UI. But as you've seen in the curation hub, you have full ability to merge, unmerge, and make edits to the or updates to the the records as well.
Yeah. Great. Can Tamer notify downstream systems of changes made through the UI or automated mastering processes?
Yeah. Absolutely. So that's that's where the webhooks really come in. So you can set webhooks on different events, whether it's record changes, record updates. And in fact, when Elliot showed the three sixty page down at the bottom, there was that record history.
And so those are the various events that are happening through the record. It's to the record itself. So if a change is made, let's say Elliot goes and curates a record and within Tamer's UI, for example, updates a a field, then that triggers a webhook to say, oh, this field has changed. So that's one way to notify downstream systems of those sorts of changes as well.
You can yeah. There's lots of options in terms of how much notification you want. Do you want it at a field level or particular tables to to have that run through? So where we see that being particularly impactful is once users have gone through and built out that master and now Tamer is that is that central hub for curating data or taking updates.
You got downstream systems which want to know about them as soon as possible. So the answer to that is configure those webhooks and have those notifications. Those applications can then choose to take that webhook payload, which does have details of a change, who made the change, or they may want to take additional action and maybe pull other data through Tamer's APIs as well. So one example being if if a if you're doing a household in use case, say, or or patient provider use case, Maybe a change is made to, yeah, the health care provider.
And in that case, you may want to take an update at the same time for the organization or the patient is referred to. So, typically, you see the webhook as the first trigger, and then there's some actions to take on the consuming side to decide what else what other data do you want to pull as well.
Great. Okay. The last one in this set is how are confidence thresholds configured or defined?
Yeah. And I'm actually looking for it a little bit more as well. It ties together with question with George as well. He asked if we use more than one field to match the different entities and if they have different weights and using different fields and to adjust that.
And that definitely all ties in together with the fact that that's where a lot of our patents and technology lies. Right? So, yes, Tamer uses multiple fields and multiple attributes to come up with a cluster uniformity score. And if it passes or exceeds a certain threshold, it's able to cluster those records together on a lot of different factors.
And those attributes have different weightages. Right? And those weightages where that decision tree and the path lie. That being said, in terms of answering the question of how are confidence thresholds configured and defined, the definition of the uniformity scores you're able to adjust adjust after the fact.
So if you have particular attributes that you want to cluster records on based on a business rule or the opposite, not cluster records based on a particular business rule, we allow you to tweak that after the fact. And within the UI as well, if you wanted to identify and know a place to start, we allow you to actually filter based on uniformity score. So you're able to start from the least confident to the most confident of how records are brought together, and you have that both on a record level and an attribute level. So what I mean by that is if you want to see the uniformity score for just the first name or just the company name and adjust it from there and see the list of confidence scores that way, you have full ability to do so.
But the the weightages and and how Tamr comes up with the logic and confidence score to cluster those together, that's what's happening behind the scenes, and that's where our patents lie in terms of the machine learning models.
Excellent. Thank you, Elliot.
One question from Carlos. What kind of patents does Tamer have? So you can go to tamer dot com backslash patents for these details. And we have, I think, one or two more questions.
From George, does Tamer use more than one field to match the different entities? And if yes, do you have different weights? So for example, we could use company name, email, or primary contact, address, phone number, etcetera. Can they all be used and with different weights?
Yeah. Absolutely. Yep.
So a great example of that is matching individuals where you have person's name, their address, maybe their phone number or email. If if you have folks living in a very large apartment building, yeah, address line one may be weighted differently to address line two so that you're bringing together things in the correct manner, similar to companies in a business park as well. So or we often see a lot of research in higher education institutions where lots of similarity in in in a lot of details, but maybe it's one field where most of distinguishing characteristics apply. So in that manner, we can focus in on values that are specific to a particular location, but at the same time, also filter out repetitive repetitive values or or filler values as well. So we can take both approaches, but, yeah, multiple fields and pulling together different different permutations.
Great. Thank you, Ravi. One more question. Is the cost for TMR annual, and how is it priced?
So it is an annual price. Yes. And it's priced based on golden record count, primarily. So other solutions will focus on how much volume data is going in. Tamer's focused on those golden records being produced on output.
So, yeah, definitely, I'm happy to follow-up with more details as you have volumes if you could share with us. But, yeah, certainly, it's focused on what gets out of Tamer in terms of the output of the records and how you access it.
Of course. And you can always go to tamer dot com backslash demo to request a personalized demo and get in touch with our sales team.
So that wraps up our webinar today. Thank you so much for joining us today, and thank you, Ravi and Elliot.